Engenharia de Prompts para Pesquisa em Administração - Parte 1 (O que é e como funciona um LLM como o ChatGPT)
Vamos aprender o básico de como desenvolver instruções para LLMs (large language models) como ChatGPT, Bard, Llama, entre outros.
Fellipe Martins
11/28/20236 min ler
Se você não sabe usar bem o ChatGPT....
Para quem tem estudado o campo de processamento de linguagem natural e geração de linguagem natural, o surgimento de ferramentas como ChatGPT foi algo esperado. O resto do mundo, que não tinha ouvido falar antes nesse tipo de ferramenta, foi tomado em choque.
Após um ano aproximadamente do lançamento comercial do ChatGPT, e do subsequente crescimento vertiginoso de opções de geração de textos, dados, imagens e outros com base em inteligência artificial, muitos pesquisadores em administração ficam ainda sem saber como lidar com tais ferramentas. Ou, usam de forma rasa e não tem os resultados potenciais do bom uso destas, por desconhecimento de como essas ferramentas funcionam.
Se você não me conhece ainda, eu me chamo Fellipe Martins e sou professor / pesquisador no programa de Mestrado e Doutorado em Administração da Universidade Presbiteriana Mackenzie. Mas antes fui por uns bons anos professor num doutorado em Informática e Gestão do Conhecimento em outra instituição, o que me faz ter uma "perninha" em outra área que é muito útil para fazer esta ponte entre ferramentas de IA e administração.
Nessa série de tutoriais, vamos começar com algumas coisas básicas - de forma simples, (1) o que é e como funciona uma ferramenta de LLM (large language models ou grandes modelos de linguagem) como o ChatGPT (e o mesmo vale para a maior parte de ferramentas similares); (2) como nos relacionamos com essas ferramentas (vai por mim, é importante!); e (3) como começar a tirar mais proveito dessas ferramentas por meio de prompts (instruções inseridas por você caro amigo!).
Hoje vamos começar com a primeira parte! E se você gostou da proposta, continue lendo e em breve eu faço mais tutoriais!
Antes de mais nada, ética!
Como falei antes, já passou um ano mais ou menos do lançamento do ChatGPT. Professores ficaram inicialmente com medo e aversão, para um processo de aceitação e agora a uma incorporação ativa de ferramentas LLM (large language models, ou grandes modelos de linguagem).
Como professor, eu aprecio ferramentas que auxiliem no desenvolvimento de alunos porque eu sei que, lá no fundo, a responsabilidade sobre o processo de ensino aprendizagem, apesar de todas as correntes modernas, continua sendo minha missão. Da mesma forma que em épocas anteriores usar um celular assustava e hoje é normal, o mesmo vai acontecendo todo dia com LLMs. É do professor a tarefa de pensar e planejar como integrar um LLM num processo de ensino, para que a ferramenta seja útil e não como muleta ou tabu.
Mas o lado pesquisador é diferente. Nós somos constantemente avaliados pelos pares pela nossa capacidade de desenvolver contribuições teóricas e técnicas originais, que não podem (ou pelo menos ainda não são possíveis de) serem terceirizadas por LLMs, nem mesmo os mais poderosos hoje (mas vai que muda...).
Acredito que o grosso da discussão ética sobre LLMs em pesquisa está mais ou menos definida. Primeiro, há atividades em um projeto / artigo / manuscrito / etc. claramente antiéticas (plágio, cópia, etc) e que continuam sendo antiéticas usando o ChatGPT, por exemplo. Outras sempre foram consideradas éticas (revisão de texto, tradução, formatação, etc.) e que continuam sendo éticas mesmo quando feitas por ferramentas e não pessoas.
Há sim uma área cinzenta em que não temos certeza ou ainda não desenvolvemos parâmetros para julgar ética na interseção de algumas atividades e inteligência artificial. Mas deixo essa discussão para outro momento, inclusive em um editorial para o primeiro número de 2024 da Mackenzie Management Review / Revista de Administração Mackenzie, de onde sou editor-chefe. Aviso vocês no Instagram quando sair!
De toda forma, a heurística simples que eu proponho é: se for ético fazer uma atividade com outra pessoa, é ético fazer com uma ferramenta. Da mesma forma, se é antiético fazer uma atividade sem ferramenta, continua antiético com ferramenta. Na dúvida (a tal área cinzenta), seja prudente e transparente.
Já que demos o spoiler da parte ética, vamos em frente!
O que é e como funciona
Para não ser repetitivo nem tecnicamente impreciso, vou apresentar uma versão mais metafórica do que são as ferramenta de LLM e como elas funcionam.
Tente completar a seguinte frase:
Eu levei o meu _____ para o veterinário.
É muito provável que você tenha completado com gato, cachorro, pet ou animal de estimação. É um pouco menos provável, mas plausível, que você tenha optado por porquinho da índia, lagarto ou macaco. É muito menos provável que você escolha uma pessoa, objeto ou máquina. E muito menos provável ainda, e talvez seja preocupante, se você escolher levar um conceito abstrato (como amor) ao veterinário - a menos que nesse caso você goste do veterinário de outra forma não profissional...
Por que pensamos logo em gato ou cachorro? A nossa cabeça trabalha muitas vezes de forma probabilística. O que é mais plausível, acreditável, esperável - levar um cachorro ou torno mecânico ao veterinário? Isso ocorre porque associamos a palavra veterinário a um mapa de todas as combinações possíveis ou prováveis e decidimos filtrar pela melhor combinação - ou seja aquela mais "natural" (esperada), mesmo que não seja a real ou intencionada - afinal você pode levar um torno mecânico ao veterinário (ou mesmo o amor) e não é incorreto gramaticalmente, nem impossível de acontecer.
Essa é a lógica por trás de um algoritmo básico de processamento de linguagem natural, os word embeddings (aqui você tem uma visão mais técnica dessa e outras técnicas). Word embeddings são uma técnica usada em processamento de linguagem natural, onde palavras são transformadas em números de uma forma que captura seu significado e as relações entre elas, por meio de vetores. Vou tentar explicar de forma simples...
Imagine que cada palavra é um pássaro e cada tipo de pássaro gosta de voar com pássaros semelhantes. Em word embeddings, palavras com significados ou usos semelhantes são como pássaros que voam juntos - são mais prováveis de aparecerem no mesmo cenário / situação / ambiente.
Voltando ao nosso exemplo, as palavras "gato" e "cachorro" podem ser representadas por números que as colocam próximas uma da outra, porque ambas são animais de estimação, ambas comem ração, ambas são levadas em coleira, ambas vão ao veterinário, e assim por diante, aumentando a sua probabilidade de aparecerem no mesmo contexto. Isso é feito analisando grandes quantidades de texto e observando como as palavras são usadas em diferentes contextos. Assim, o computador aprende a associar palavras com significados e usos semelhantes, mesmo sem entender o significado real das palavras como um humano faria.
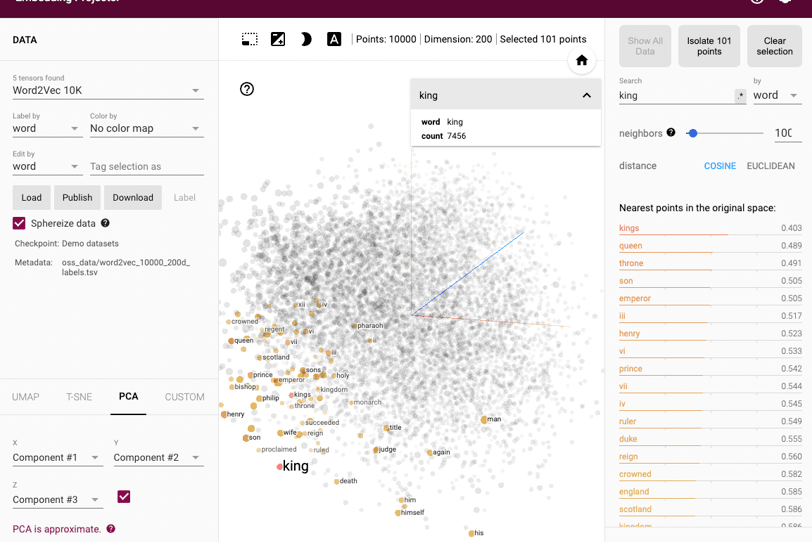
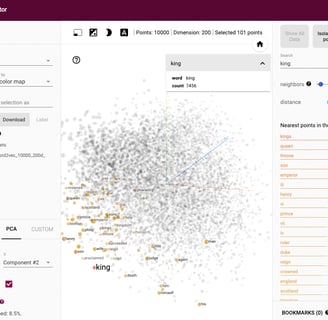
De forma mais técnica, as palavras se agrupam em relação a vetores (imagine umas setas imaginárias cruzando inúmeras dimensões). Se pegarmos palavras como helicóptero, drone e foguete, podemos inferir que há dois vetores que associam essas palavras (todos "voam" e todos tem "motor") - na verdade há mais vetores, provavelmente muito mais. Se pegarmos palavras como ganso, águia e abelha, também são associadas com "voar", mas também são associadas a um vetor de "asas". Se você tiver um número gigantesco de palavras e igualmente de vetores, você começa a entender porque essas ferramentas são chamadas LLMs (grandes modelos de linguagem).
Esses mesmos vetores não são usados não para associar palavras mas para fazer operações matemáticas entre elas! A palavra rei é associada a um vetor de gênero (homem) e a um vetor de nobilidade (realeza). Assim, você consegue fazer operações como:
Rei - Homem = Rainha
Você deslocou o modelo numa direção em que a palavra mais provável (a que mais se aproxima numa tabela de probabilidades) naquela região é rainha.
Esse é o "truque" - o computador "entende" contexto por meio de relações probabilísticas, sem entender, no sentido humano, o que é contexto. E no final, tem um resultado muito próximo, talvez quase igual ao normal. Se você já usa um LLM você deve saber que, se bem usado, é difícil saber se o texto foi escrito por uma máquina.
Mas, isto também é uma fraqueza de um LLM - vamos ver mais adiante. Deixo duas limitações: (1) sem parametrização a produção de um texto por LLMs pode ser "sem graça" - porque o resultado vai ser o mais esperado; e (2) preconceitos embutidos em grandes volumes de texto tendem a ser aprendidos pelos modelos, se não houver curadoria.
Os LLMs modernos são muito mais maduros que word embeddings. A maioria usa hoje uma arquitetura chamada de transformers, que usa uma outra lógica mais robusta (as camadas de atenção) para fazer isso que mostrei para vocês num nível surreal de aprimoramento.
Mas para efeito de ilustração, vou deixar aqui um tensor interativo, para você verificar como funcionam as proximidades entre palavras. (Um tensor é uma entidade geométrica que generaliza a noção de vetores, escalares e matrizes. É um conjunto de objetos matemáticos ou físicos relacionados entre si, que determinam uma relação entre duas outras entidades matemáticas ou físicas)